
Unique IDs are pretty much used everywhere and in every application. They are used to identify a user, a product, a transaction, a session, etc. That way we can, for example, assign a transaction made to a specific user, and not by mistake another one. In this article, I’ll show you how I generate unique IDs in my applications and give them a second usage as well.
How to get unique IDs?
There are several ways of getting a unique ID per user. Obviously some people probably do stuff like
const min = 1000000;
const max = 9999999999;
const id = Math.floor(Math.random() * max) + min;Though I don’t really recommend that as it is obviously not really unique. You can, and will, end up with twice the same ID generated. Of course you can check in the database if that ID already exists and generate a new one if it’s the case, but you get my point
Auto incrementing integer
Although this is a very basic and widely used method, I’d rather not use this. An example on how this looks like in a database would be something close to that:
| id | username | password | created_at |
|---|---|---|---|
| 1 | john | some_hash | 1667329399 |
| 2 | jane | some_hash | 1667329404 |
| 3 | jack | some_hash | 1667329412 |
Here we can clearly see the IDs incrementing every time one by one.
UUID
UUIDs are a very common way of getting a unique ID. They are 128-bit numbers that are unique. UUIDs are very useful because they are unique, yes there is a tiny chance you can get the same ID generated twice, and they are not sequential. They are also very easy to generate. We can, for example, generate one via the terminal using the following command:
~ 🕙 20:07:00 ❯ uuidgen 67DB31FB-1887-4372-A8B0-E87C092D7D11
As you have expected, this UUID will take space in your database but that doesn’t really matter that much, your database ends up looking like that when you use UUIDs:
| id | username | password | created_at |
|---|---|---|---|
| 45915234-74BE-499A-B7D5-D6D4882DA5B7 | john | some_hash | 1667329399 |
| 885A26B8-C7CA-4C84-A871-0E89AF4997BD | jane | some_hash | 1667329404 |
| 689E682B-35C8-4594-A0D7-5893626B7B1D | jack | some_hash | 1667329412 |
Now let me introduce to you Spaceflake, a distributed generator to create unique IDs with ease; inspired by Twitter’s Snowflake
What is a Spaceflake?
A Spaceflake is very simple, it’s an ID based on the Snowflake algorithm of Twitter, which they are actively using, and it is slightly edited to fit my needs. The algorithm is pretty simple:
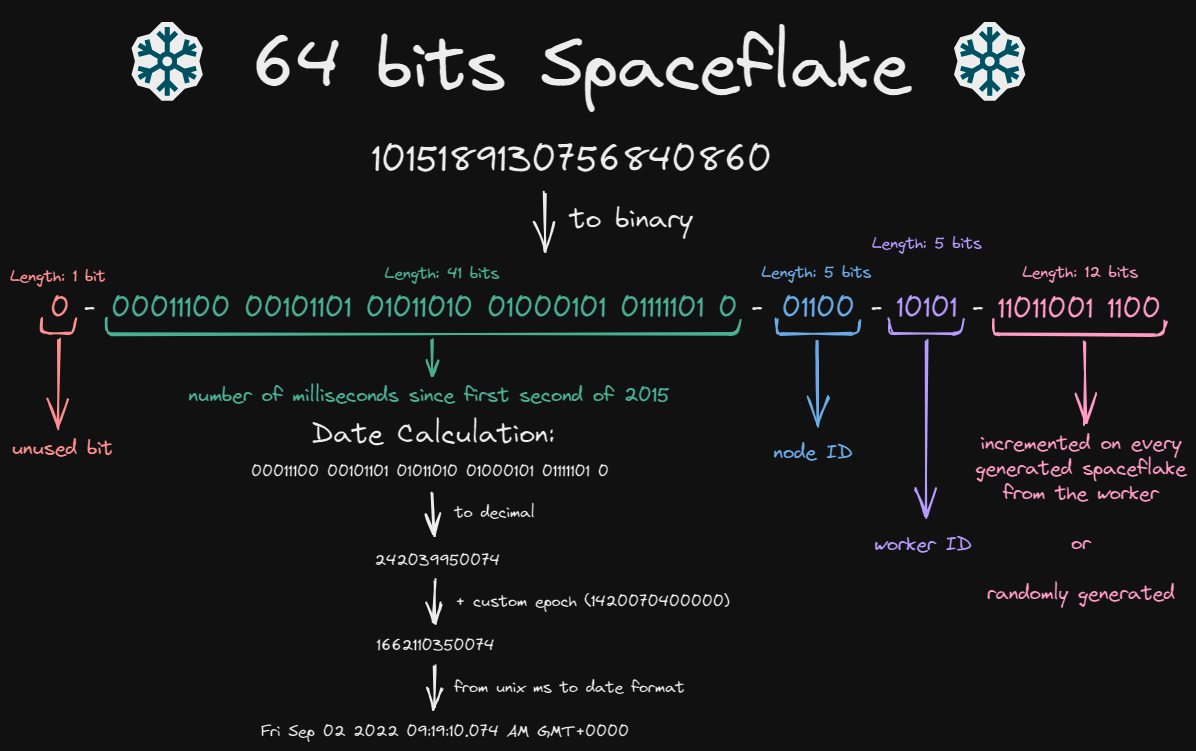
As you can see, a Spaceflake is composed of 4 main parts:
- Timestamp: The timestamp is the milliseconds elapsed since the base epoch, it is not necessarily the Unix epoch, when the ID was generated.
- Node ID: The node ID represents the ID of the node that generated the Spaceflake. It is a number between 0 and 31.
- Worker ID: The worker ID represents the ID of the worker that generated the Spaceflake. It is a number between 0 and 31.
- Sequence: The sequence is the number of Spaceflakes generated by the worker on the node. It is a number between 0 and 4095.
With these specifications of the algorithm, we can theoretically generate up to 4 million unique IDs per millisecond
Workers & Nodes = Spaceflake Network
A Spaceflake Network is a very basic concept where you have multiple independent nodes that themselves consist of multiple workers. These workers are the ones that can generate Spaceflakes.
Ideally a Spaceflake Network represents your entire application, or company. Each node represents a single service/server or application within the company, and each worker represents a single process which can generate a Spaceflake for a specific purpose. This way you can easily identify where a Spaceflake was generated by looking at its node ID and worker ID.
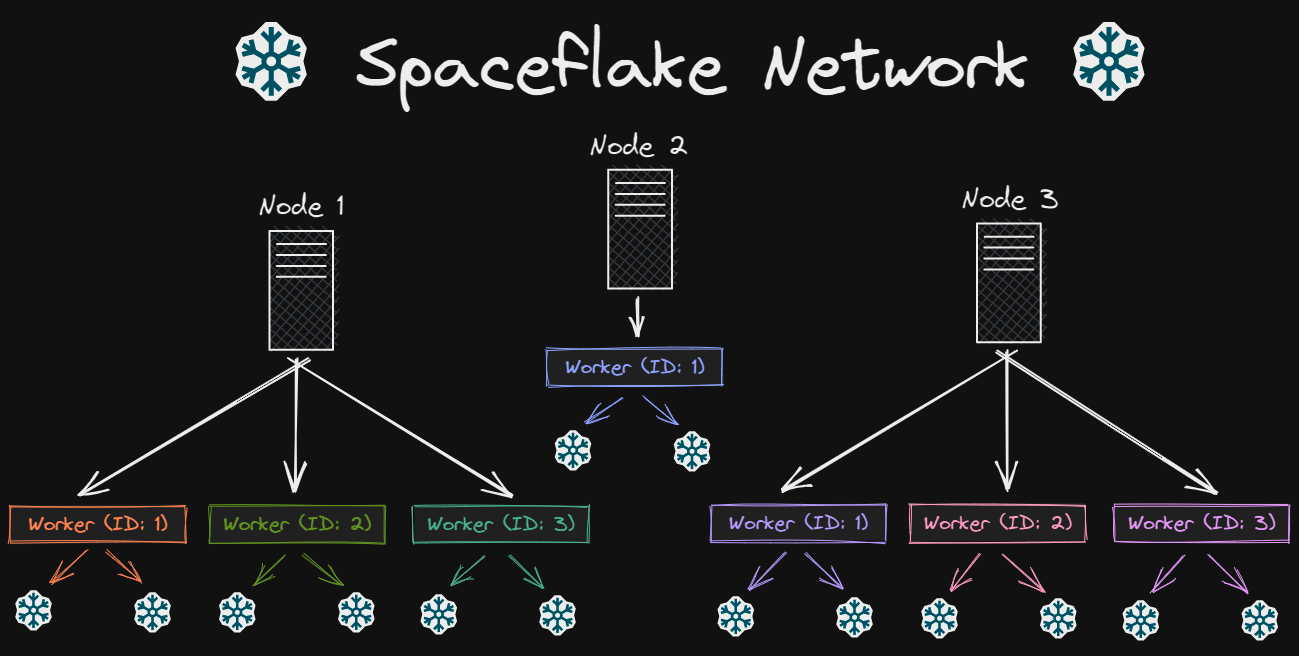
In the example above we can can consider Node 1 as being the API/backend of your application. The Worker (ID: 1) would be responsible for generating Spaceflakes for user IDs. The Worker (ID: 2) would be responsible for generating Spaceflakes for blog post IDs. That way we can easily identify where a Spaceflake was generated and for what purpose. Then we also have the Node 2 which may be the logging system of your entire infrastructure, and the IDs generated would be generated by the Worker (ID: 1).
In the end you are free to use them as you wish, just make sure you use these nodes and workers to be able to identify the Spaceflake - which is also the idea behind it.
Why did I create Spaceflakes?
Now you may ask me
“Why on Earth did you create this???”
As a matter of facts lots of people have already asked me this…
To explain my decision, let’s go back to the example of the database above with UUIDs. I intentionally added a created_at field in the database as it is very useful to know when a user, or a post, was created. With Spaceflakes, and Snowflakes, you have the creation time of the ID built-in ((spaceflake >> 22) + BASE_EPOCH), so you don’t need to store it separately in a new column of your database. This is very useful as it removes unnecessary columns, and it also makes it easier to sort your data by creation time. Your database would then look like that:
| id | username | password | |
|---|---|---|---|
| 1037425364332843009 | john | some_hash | |
| 1037425458566270978 | jane | some_hash | |
| 1037425546889924611 | jack | some_hash |
Another reason is that I use Go (duh) for all my different backends, and I wanted to implement my own way of generating unique IDs that are just like Snowflakes. The goal was to make it as easy as possible to use, and to be able to use it in any project I am working on.
Some issues I’ve faced during development
Go is fast

Yes, Go is fast; this was also my first issue. The reason behind that is that at first I made the sequence random, which was definitely not the best idea - though I’ve kept it in case I want to use it one day. The issue is that, as you’ve guessed, the sequence is from 0 to 4095, which means that it can only generate 4096 unique IDs per millisecond. This is not a lot, and it is definitely not enough to make sure to have a unique ID for each Spaceflake generated within a millisecond. So I had to change it to be incremental.
Incremental is not enough for bulk generation
So let’s suppose someone wants to migrate their database to use Spaceflakes instead of UUIDs. They would have to generate a lot of Spaceflakes, and they would have to do it as fast as possible. This is where the issue comes in. If you generate a Spaceflake every millisecond, you can only generate 4096 Spaceflakes per millisecond. This is, once again, not a lot. So I had to make the node ID and the worker ID incremental as well when using the BulkGenerate() function.
The code is a bit madness, but it’s working (at least I think so).
// BulkGenerate will generate the amount of Spaceflakes specified and auto scale the node and worker IDs
func BulkGenerate(s BulkGeneratorSettings) ([]*Spaceflake, error) {
node := NewNode(1)
worker := node.NewWorker()
worker.BaseEpoch = s.BaseEpoch
spaceflakes := make([]*Spaceflake, s.Amount)
for i := 1; i <= s.Amount; i++ {
if i%(MAX12BITS*MAX5BITS*MAX5BITS) == 0 { // When the total amount of Spaceflakes generated is the maximum per millisecond, such as 3'935'295
time.Sleep(1 * time.Millisecond) // We need to sleep to make sure the timestamp is different
newNode := NewNode(1) // We set the node ID to 1
newWorker := newNode.NewWorker() // And we create a new worker
newWorker.BaseEpoch = s.BaseEpoch
node = newNode
worker = newWorker
} else if len(node.workers)%MAX5BITS == 0 && i%(MAX5BITS*MAX12BITS) == 0 { // When the node ID is at its maximum value
newNode := NewNode(node.ID + 1) // We need to create a new node
newWorker := newNode.NewWorker() // And a new worker
newWorker.BaseEpoch = s.BaseEpoch
node = newNode
worker = newWorker
} else if i%MAX12BITS == 0 { // When the worker ID is at its maximum value
newWorker := worker.Node.NewWorker() // We just create a new worker
newWorker.BaseEpoch = s.BaseEpoch
worker = newWorker
}
spaceflake, err := generateSpaceflakeOnNodeAndWorker(worker, worker.Node) // We generate the Spaceflake on the node and worker specified
if err != nil {
return nil, err
}
spaceflakes[i-1] = spaceflake // i starts at 1, so we need to subtract 1 to get the correct index
}
return spaceflakes, nil
}Now we can make a bulk generation of up to 3’935’295 Spaceflakes per millisecond, which is a lot more than 4096 without auto scaling. Once we hit that maximal amount, we need to sleep for 1 millisecond to make sure the timestamp is different, and we need to create a new node and a new worker.
That is another problem solved
Spaceflakes are big numbers
Last but not least, I learned that big numbers are pain if not handled as string within an API.
This was exactly what happened to me when using Spaceflakes for one of my API; I generated a Spaceflake - 144328692659220481 - and made an endpoint to get the user ID. When making a GET request to the endpoint with a browser, I got the following json:
{
"id": 144328692659220480
}Yes yes, there is a small difference - it’s right here: 144328692659220480. Now this may be a small difference, but it is a difference and we do not want that. The only solution is to make the API return the ID as a string. On the client side, we can then convert it to a number if we want to - for example by using this:
spaceflakeID := "144328692659220481" // Will be the value returned by the API
id, _ := strconv.ParseUint(spaceflakeID, 10, 64)
sequence := spaceflake.ParseSequence(id)This will then return the correct sequence of the Spaceflake.
How to use Spaceflakes?
Using Spaceflakes is super simple, if you have a Go project, you can just download the package with
go get github.com/kkrypt0nn/spaceflakeAnd then you can use it in your project by importing it and generate a Spaceflake:
package main
import (
"fmt"
"github.com/kkrypt0nn/spaceflake"
)
func main() {
node := spaceflake.NewNode(5)
worker := node.NewWorker() // If BaseEpoch not changed, it will use the EPOCH constant
sf, err := worker.GenerateSpaceflake()
if err != nil {
panic(err)
}
fmt.Println(sf.Decompose()) // map[id:<Spaceflake> nodeID:5 sequence:1 time:<timestamp> workerID:1]
}There are other examples you can check out in the examples folder of the repository.